PaddleOCR是基于百度飞桨的开源文字识别模型,能够支持多文字类型识别和手写体识别,识别效果较好。
本文将从零开始,记录PaddleOCR 3.x的安装与使用过程。
安装飞桨框架
进入PP飞桨官网,复制适合自己操作系统及芯片厂商的安装命令。
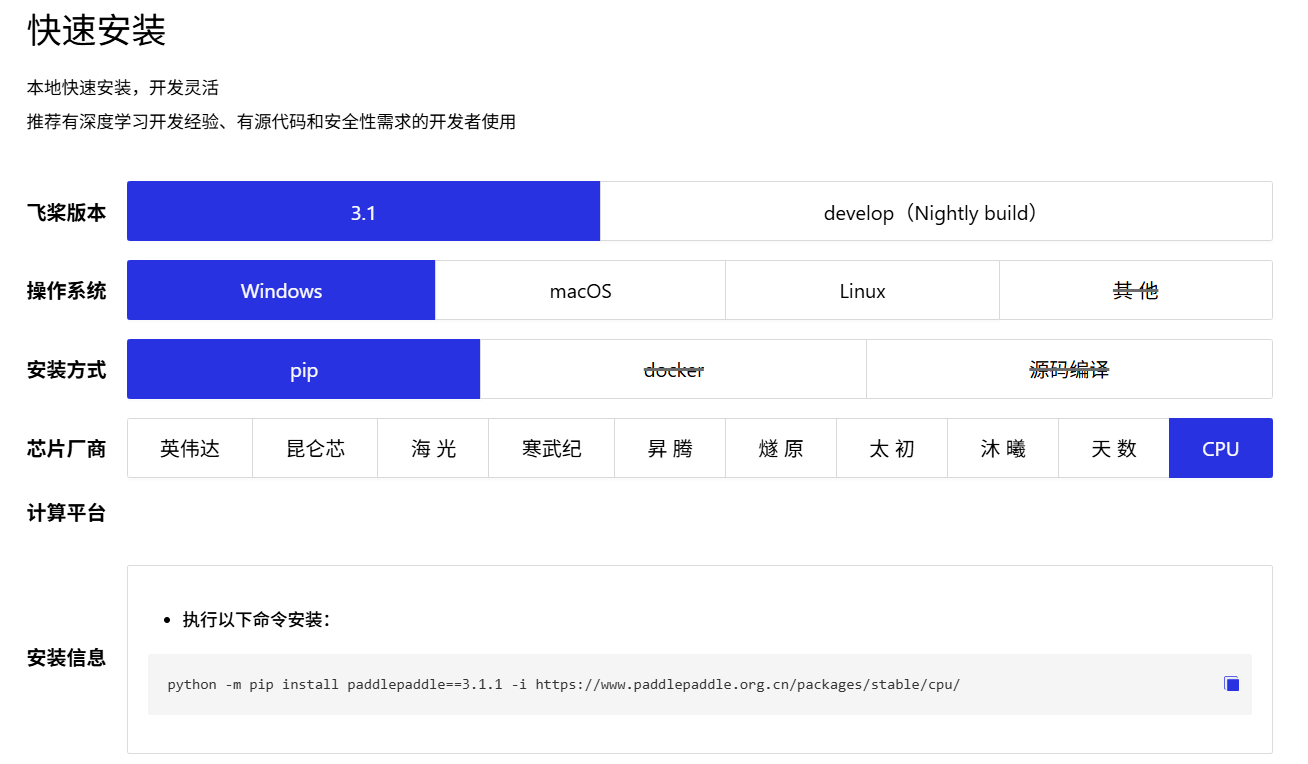
使用Windows系统、纯CPU运行的,可以使用以下命令安装:
python -m pip install paddlepaddle==3.1.1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
安装PaddleOCR
执行以下命令完整安装PaddleOCR:
python -m pip install "paddleocr[all]"
运行示例代码
准备一张测试图片test.png放在与代码文件同级的目录下。

运行以下示例代码:
from paddleocr import PaddleOCR
# 初始化 PaddleOCR 实例
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False)
# 对示例图像执行 OCR 推理
result = ocr.predict(input="./test.png")
# 可视化结果并保存 json 结果
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
代码运行后,会输出识别后的文本框坐标、文本等信息,并在代码同级目录下自动生成output目录,用于存放OCR识别后的可视化结果。
下图为运行成功后,output目录下生成的可视化结果:

代码详解
上述代码通过PaddleOCR()实例化对象时,可进行参数设置,具体设置项如下:
参数 | 参数说明 | 参数类型 | 默认值 |
|---|
doc_orientation_classify_model_name
| 文档方向分类模型的名称。如果设置为None,将会使用产线默认模型。 | str|None
| None
|
doc_orientation_classify_model_dir
| 文档方向分类模型的目录路径。如果设置为None,将会下载官方模型。 | str|None
| None
|
doc_unwarping_model_name
| 文本图像矫正模型的名称。如果设置为None,将会使用产线默认模型。 | str|None
| None
|
doc_unwarping_model_dir
| 文本图像矫正模型的目录路径。如果设置为None,将会下载官方模型。 | str|None
| None
|
text_detection_model_name
| 文本检测模型的名称。如果设置为None,将会使用产线默认模型。 | str|None
| None
|
text_detection_model_dir
| 文本检测模型的目录路径。如果设置为None,将会下载官方模型。 | str|None
| None
|
textline_orientation_model_name
| 文本行方向模型的名称。如果设置为None,将会使用产线默认模型。 | str|None
| None
|
textline_orientation_model_dir
| 文本行方向模型的目录路径。如果设置为None,将会下载官方模型。 | str|None
| None
|
textline_orientation_batch_size
| 文本行方向模型的batch size。如果设置为None,将默认设置batch size为1。 | int|None
| None
|
text_recognition_model_name
| 文本识别模型的名称。如果设置为None,将会使用产线默认模型。 | str|None
| None
|
text_recognition_model_dir
| 文本识别模型的目录路径。如果设置为None,将会下载官方模型。 | str|None
| None
|
text_recognition_batch_size
| 文本识别模型的batch size。如果设置为None,将默认设置batch size为1。 | int|None
| None
|
use_doc_orientation_classify
| 是否加载并使用文档方向分类模块。如果设置为None,将使用产线初始化的该参数值,默认初始化为True。 | bool|None
| None
|
use_doc_unwarping
| 是否加载并使用文本图像矫正模块。如果设置为None,将使用产线初始化的该参数值,默认初始化为True。 | bool|None
| None
|
use_textline_orientation
| 是否加载并使用文本行方向模块。如果设置为None,将使用产线初始化的该参数值,默认初始化为True。 | bool|None
| None
|
text_det_limit_side_len
| 文本检测的图像边长限制。 | int|None
| None
|
text_det_limit_type
| 文本检测的边长度限制类型。 | str|None
| None
|
text_det_thresh
| 文本检测像素阈值,输出的概率图中,得分大于该阈值的像素点才会被认为是文字像素点。 | float|None
| None
|
text_det_box_thresh
| 文本检测框阈值,检测结果边框内,所有像素点的平均得分大于该阈值时,该结果会被认为是文字区域。 | float|None
| None
|
text_det_unclip_ratio
| 文本检测扩张系数,使用该方法对文字区域进行扩张,该值越大,扩张的面积越大。 | float|None
| None
|
text_det_input_shape
| 文本检测的输入形状。 | tuple|None
| None
|
text_rec_score_thresh
| 文本识别阈值,得分大于该阈值的文本结果会被保留。 | float|None
| None
|
text_rec_input_shape
| 文本识别的输入形状。 | tuple|None
| None
|
lang
| 使用指定语言的 OCR 模型。 附录中的表格中列举了全部支持的语言。 | str|None
| None
|
ocr_version
| OCR 模型版本。 PP-OCRv5:使用PP-OCRv5系列模型; PP-OCRv4:使用PP-OCRv4系列模型; PP-OCRv3:使用PP-OCRv3系列模型。
注意不是每个ocr_version都支持所有的lang,请查看附录中的对应关系表。 | str|None
| None
|
device
| 用于推理的设备。支持指定具体卡号: CPU:如 cpu 表示使用 CPU 进行推理; GPU:如 gpu:0 表示使用第 1 块 GPU 进行推理; NPU:如 npu:0 表示使用第 1 块 NPU 进行推理; XPU:如 xpu:0 表示使用第 1 块 XPU 进行推理; MLU:如 mlu:0 表示使用第 1 块 MLU 进行推理; DCU:如 dcu:0 表示使用第 1 块 DCU 进行推理; None:如果设置为None,将默认使用产线初始化的该参数值,初始化时,会优先使用本地的 GPU 0号设备,如果没有,则使用 CPU 设备。
| str|None
| None
|
enable_hpi
| 是否启用高性能推理。 | bool
| False
|
use_tensorrt
| 是否启用 Paddle Inference 的 TensorRT 子图引擎。如果模型不支持通过 TensorRT 加速,即使设置了此标志,也不会使用加速。
对于 CUDA 11.8 版本的飞桨,兼容的 TensorRT 版本为 8.x(x>=6),建议安装 TensorRT 8.6.1.6。 | bool
| False
|
precision
| 计算精度,如 fp32、fp16。 | str
| "fp32"
|
enable_mkldnn
| 是否启用 MKL-DNN 加速推理。如果 MKL-DNN 不可用或模型不支持通过 MKL-DNN 加速,即使设置了此标志,也不会使用加速。 | bool
| True
|
mkldnn_cache_capacity
| MKL-DNN 缓存容量。 | int
| 10
|
cpu_threads
| 在 CPU 上进行推理时使用的线程数。 | int
| 8
|
paddlex_config
| PaddleX产线配置文件路径。 | str|None
| None
|
执行ocr.predict()方法后会返回识别结果列表,我们可以从中获取到文本检测框位置、预测置信度、文本识别结果等信息。
为了加深认识,现在我们借助Pillow库,将PaddleOCR识别结果的检测框和文字在图像上画出来。
未安装Pillow库的可以使用以下命令安装:
pip install pillow
从PaddleOCR识别结果中获取检测框的坐标数组和文本识别结果列表:
# 检测框的坐标数组
boxes = result[0]['rec_boxes']
# 文本识别结果列表
texts = result[0]['rec_texts']
执行以下代码,通过循环将每个检测框和文本绘制在图片上:
from PIL import Image, ImageDraw, ImageFont
# 打开图片
image = Image.open('./test.png')
# 创建绘画的对象
draw = ImageDraw.Draw(image)
# 指定文字字体为宋体
font = ImageFont.truetype("simsun.ttc", size=20)
# 把每个检测框和文字绘制在图片上
for i in range(len(boxes)):
draw.rectangle(boxes[i], outline="red", width=2)
draw.text(boxes[i], rec_texts[i], fill="yellow", font=font)
image.show()

通过上述操作,我们就已经掌握了PaddleOCR文字识别的基础使用方法。